
Anteriormente había redactado un artículo donde hacia referencia a los buscadores que respetaban tu privacidad, presuntamente, enlace (https://write.privacytools.io/gatooscuro/motores-de-busqueda-que-respetan-la-privacidad) ¡hoy vengo a derribarlos! Con una traducción del artículo original del compañero Digdeeper quién se inspiró en dicha problemática (https://digdeeper.neocities.org/ghost/search.html)
- Introducción-
- El problema sin índice propio-
- Lista de proveedores-
- SearX-
- Wiby-
- Swisscows –
- StartPage –
- DuckDuckGo –
- Qwant –
- MetaGer –
- Jive Search (Muerto) –
- Mojeek –
- Ecosia –
- Oscobo –
- Discrete Search –
- Gibiru –
- Peekier –
- FindX –
- Resumen –
Introducción
La mayoría de nosotros los utilizamos todos los días (generalmente varias veces, de hecho), por lo que es importante considerar cuidadosamente su selección de opciones. No solo queremos grandes resultados, sino que, dado que a menudo compartimos algunos datos realmente confidenciales con ellos (como médicos, viajes), es mejor que no estén haciendo cosas sucias con eso. También hay varias funciones adicionales que nos gustaría que proporcionaran nuestros motores de búsqueda. Ahora bien, ¿por qué utilicé la frase selección de opciones? Porque, como verá, la situación con los motores de búsqueda no es tan buena como con los proveedores de correo electrónico, por lo que nos vemos obligados a cambiar, ya que no hay uno que tenga todo lo que necesitamos. Sin más preámbulos, veamos lo que está disponible:
El problema sin índice propio
Un tiempo después de terminar este artículo tuve una “revelación”: la situación con los motores de búsqueda es incluso peor de lo que pensaba antes. Aparte de Wiby (que tiene muy pocos sitios en los que se pueden realizar búsquedas) y Mojeek, los motores de búsqueda mencionados aquí dependen de otros para obtener resultados. Por “otros” me refiero a Google, Bing o Yahoo, tres violadores masivos de la privacidad . Cuando busca, digamos, Swisscows, la consulta se envía primero a Swisscows, que la reenvía a Bing, que luego le devuelve el resultado a Swisscows y finalmente a usted. Hay varios problemas con esta configuración:
- Independientemente de la política del motor, los términos de búsqueda se almacenan en los servidores de los infractores y pueden contener información confidencial.
- El motor debe firmar un acuerdo con el infractor para poder representar sus resultados, y el contenido de ese acuerdo no se le revela y puede incluir la recopilación de datos. A menos que lo hagan a la Scroogle way… (https://searchengineland.com/scroogle-org-is-gone-forever-says-site-owner-112245) (pista: murió)..
- Los resultados aún serán censurados si esa es la política del infractor.
- El infractor puede bloquear el motor en cualquier momento.
Esto no es tan diferente de usar Invidious, Nitter, Facebook Container o clientes personalizados de Discord para sus respectivos servicios: el infractor aún toma las decisiones. Y nosotros, como las esposas que dependen de sus maridos abusivos, seguimos regresando por más con la esperanza de poder evitar parte del daño. Pero, a medida que dependemos cada vez más de los infractores, se hace más difícil deshacerse de ellos. Tenga esto en cuenta mientras lee las siguientes recomendaciones.
Lista de proveedores
SearX

SearX es un proxy de código abierto para motores de búsqueda (en su mayoría infractores como Google o Bing, pero también Mojeek y otros) que cualquiera puede ejecutar en su propia máquina. Algunas instancias incluyen Snopyta’s (https://search.snopyta.org/), Disroot’s (https://search.disroot.org/) searx.me (https://searx.me/) (advertencia: no todas apoyan necesariamente su privacidad). El objetivo de SearX es elegir qué motores desea utilizar para los resultados , sin enviarles las solicitudes directamente. Problema número uno: las instancias a menudo son bloqueadas por los propios motores. Número dos: los resultados suelen ser muy débiles a pesar de elegir grandes proveedores. Tres: los resultados se mezclan de formas extrañas, como una página completa de resultados de un solo motor, o el mismo resultado se repite varias veces. Todos estos problemas parecen depender de la instancia utilizada. SearX solía tener un error extremadamente molesto en el que los resultados no iban más allá de la primera página, pero ya no parece y todavía lo hace, joder (pero de nuevo, depende de la instancia, la configuración, el tiempo de uso … no parece tener ese problema). Aquí está la cita de privacidad de la instancia de snopyta:
¿Qué datos recopila? – Recopilamos la menor cantidad posible. Por ejemplo, no registramos las direcciones IP ni las consultas de búsqueda que realiza con Searx.
Y de Disroot:
No se almacenan datos (dirección IP, cookie de sesión, etc.) en el servidor, a menos que sea para solucionar problemas, después de lo cual los datos de registro se eliminan del servidor.
Ahora bien, estos dos casos no son muy buenos en términos de usabilidad (sufren porque los motores de búsqueda se caen a menudo, así como el temido problema de “no hay resultados más allá de la primera página”). Inspeccione la lista de instancias (https://searx.space/) para quizás encontrar una mejor.
Las categorías de búsqueda disponibles son General, Archivos, Imágenes, TI, Mapa, Música, Noticias, Ciencia, Redes sociales y Videos (la mayor cantidad de cualquier motor enumerado aquí), y puede elegir qué proveedores de búsqueda (más de 70 disponibles) se utilizan para mostrar los resultados de cualquiera de ellos. Hay muchas otras opciones, como aplicar HTTP, eliminar rastreadores de las URL devueltas, cambiar el tema, el filtrado de contenido, etc. SearX también está integrado con Wayback Machine; esto significa que puede consultar los sitios sin conectarse directamente a ellos, incluso si ya no están disponibles. El servicio no requiere JavaScript para su funcionalidad en absoluto; incluso puede guardar la configuración a través de una URL marcada sin JS ni las cookies habilitadas.
Resumen: es posible buscar sin JS (aunque se perderán algunas funciones); puede buscar en prácticamente todos los motores relevantes; tiene integración de archivo web; puede ser privado o cebolla dependiendo de la instancia. Depende de los infractores para recibir sus resultados, y los de ejemplo particularmente apestan (independientemente de la elección del proveedor en la configuración) por alguna razón. Aún así, probablemente sea la mejor opción que existe en este momento, si encuentra una buena instancia, simplemente use otra cosa para las imágenes.
Swisscows

ACTUALIZACIÓN: es peor de lo que pensaba, ¡sigue leyendo! Si solo tuviéramos en cuenta las políticas de privacidad (https://swisscows.com/en/privacy), este motor de búsqueda poco conocido de los Alpes suizos tendría una clasificación muy alta:
No recogemos ninguna información personal de nuestros visitantes. Ninguno en absoluto. Al utilizar Swisscows no se registra su dirección IP ni se recoge el navegador que utiliza (Internet Explorer, Safari, Firefox, Chrome, etc.). No se analiza qué sistema operativo utilizan nuestros usuarios (Windows, Mac, GNU/Linux, etc.); tampoco se registra su búsqueda. No registramos absolutamente ningún dato de nuestros visitantes. La única información que almacenamos es el número de solicitudes de búsqueda introducidas diariamente en Swisscows, para medir el tráfico total de nuestro sitio web y para evaluar un desglose de este tráfico por idioma y meras estadísticas globales.
¡No se almacena ningún dato de IP o del navegador! Swisscows incluso se da cuenta (a diferencia de, por ejemplo, DuckDuckGo) de que guardar las consultas de búsqueda también es peligroso, aunque supuestamente se desvincule de la llamada información personal:
Además, es importante no almacenar ningún término de búsqueda, dado que estos también pueden contener datos personales. (Basta pensar en alguien que introduce su propio nombre y/o su número de seguro en la casilla de búsqueda.)
Por un momento pensé que -aunque no almacenen nada ellos mismos- sí que podrían compartir algunos datos con Bing (que utilizan para sus resultados), pero mis sospechas se desactivaron:
Swisscows no transmite ninguna información personal a los motores de búsqueda de terceros o a los proveedores de resultados patrocinados.
Todo esto es sólo según su política de privacidad. Sin embargo, sabemos que es mejor no creer ciegamente en una política de privacidad – especialmente cuando hay algunos problemas con la confiabilidad de Swisscows. En primer lugar, requieren JavaScript para mostrar la página, lo cual es un diseño terrible; peor aún, el código está muy ofuscado (https://digdeeper.neocities.org/txt/swisscows.txt), casi como si estuvieran ocultando algo. Recibí un informe de que Swisscows incluía enlaces de redirección en sus resultados. Al principio pensé que es algún error, pero decidí investigar y lo confirmé. Se ven así:
“http://www.smartredirect.de/redir/clickGate.php?u=[UniqueUserId?]&m=12&p=[YetAnotherID?]&q=[YourSearchQuery]&url=[TargetURL]&r=https%3A%2F%2Fswisscows.ch%3Fquery%3D[YourQuery]”
Muy turbio y contrario a su política de privacidad de no enviar tus datos a ninguna parte – porque ese servicio de redireccionamiento obtendrá absolutamente tu historial de navegación con un lo que parece ser un ID de usuario (aún no confirmado) adjunto; así como el motor de búsqueda que utilizaste (en este caso, Swisscows – pero quién sabe qué otros socios en el crimen tienen). Según este sitio de estadísticas (https://web.archive.org/web/20200202050618/http://smartredirect.de.smoothstat.com/), Smart Redirect parece recoger el historial de navegación de casi 20K personas diferentes cada día – un infractor bastante significativo, entonces. Lo que este servicio hace en realidad es mostrar resultados patrocinados que son indistinguibles de los normales aparte de una pequeña imagen junto a ellos (para la que Swisscows hace otra petición de terceros). Si hace clic en esos enlaces, su navegador hará una solicitud a una empresa de marketing de afiliación como awin o linksynergy – que también parecen contener identificadores de usuario únicos. A veces, las búsquedas desde la red Tor serán denegadas – esto podría depender del nodo de salida que obtengas. A pesar de ello, se comprometieron a no enviar tus datos a terceros – es seguro decir, entonces, que el mito de la pequeña vaca suiza privada está muerto y enterrado. Pero indaguemos un poco más:
La única razón legítima para que empecemos a recopilar datos personales sería la existencia de una orden legal o judicial, que nos obligara a hacerlo en relación con un usuario concreto, sospechoso de un delito tan grave que justificara esa violación de su intimidad.
Así que van a realizar una vigilancia selectiva sin avisarte cuando el gobierno llame a la puerta (es la gran Ley de Privacidad Suiza en acción). El motor de búsqueda también tiene este truco “familiar”, lo que significa que usted podría recibir un mensaje como:
Estimado usuario, la palabra introducida no está permitida para menores de 18 años, ya que hemos decidido la protección de los menores, la palabra “insertar término de búsqueda” está excluida de la búsqueda. Muchas gracias por su comprensión
Esto lo activan muchas consultas relacionadas con el porno y algunas relacionadas con la violencia, pero aun así puedes encontrar cosas realmente gráficas como miembros de personas cortados con bastante facilidad. Y por suerte, la información sola no parece estar censurada.
Swisscows también tiene una función de “mapa semántico” que muestra términos adicionales relevantes para la búsqueda que has escrito, acotando los resultados a lo que podrías estar buscando. Sin embargo, no la he encontrado muy útil, o quizás es que no entiendo cómo usarla. El motor de búsqueda no funciona en absoluto sin JavaScript activado (sólo se ve un fondo blanco – ¡mal diseño!). También se requiere XHR para mostrar los resultados reales (que vienen de Bing exclusivamente). Antes no funcionaba en Pale Moon, pero parece que lo han arreglado recientemente (ya sea por ellos o por PM…). Swisscows puede buscar imágenes, vídeos y noticias; “también incluye el único (AFAIK) traductor que respeta la privacidad y que, por desgracia, también es apto para familias (no puede traducir palabrotas…”) ya no incluye el traductor, así que la única cosa para la que era útil ha desaparecido. Por supuesto, el muro de la privacidad de las vacas suizas se ha derrumbado; no es seguro que podamos confiar en su política cuando ya la han roto. Así que, después de todo, Bing podría estar obteniendo tus datos. Tener problemas con Tor sella el trato aún más. Otro que muerde el polvo, como se suele decir
StartPage

Un proxy basado en la privacidad para la búsqueda de Google. Afirma “creer que la privacidad es un derecho humano fundamental”; veamos hasta qué punto siguen realmente esa creencia:
Por qué no recogemos ningún “dato personal”
Vimos los peligros de eso en la sección de DDG – donde, por ejemplo, la medición de “compromiso de eventos específicos en la página” se consideraba no personal, junto con las consultas de búsqueda reales. Pero demos el beneficio de la duda y veamos cuál es la interpretación de StartPage del término:
No registramos tu dirección IP
Con el posible obstáculo más importante fuera del camino, el tren de la privacidad funciona a toda velocidad
No servimos ninguna cookie de seguimiento o identificación
Sin contratiempos hasta ahora.
Sí medimos las cifras de tráfico general y algunas otras estadísticas -estrictamente anónimas-. Estas estadísticas pueden incluir el número de veces que se accede a nuestro servicio desde un determinado sistema operativo, un tipo de navegador, un idioma, etc.
El tren de la privacidad se está frenando. Ya hablé de los problemas de los llamados datos anónimos en la sección de DDG. Recuerda: “los únicos datos anónimos son los que no existen”. Pero la cosa se pone peor. StartPage incluye anuncios de Google (estos no pueden ser eliminados por uMatrix, sólo ocultar elementos) en la parte superior de su página de resultados de búsqueda, y:
Para permitir la prevención del fraude de clics, se comparte cierta información del sistema no identificable
¡Y el tren de la privacidad ha descarrilado totalmente! Ahora hay que confiar en la determinación de StartPage de lo que es “no identificable” como para estar seguro en manos de Google. Ahora no dicen exactamente en qué consisten esos datos – pero si es el mismo conjunto mencionado anteriormente que StartPage utiliza para sus estadísticas, definitivamente dejaría la posibilidad de revelar a alguien gracias a la huella digital del navegador. Así que StartPage envía datos potencialmente identificadores a Google. Sin embargo, no es tan malo, al menos aparentemente no los almacenan ellos mismos. Y luego está esto:
Cualquier solicitud tendrá que venir de las autoridades judiciales holandesas. Sólo cumpliremos si estamos legalmente obligados a hacerlo. Pero no es probable que recibamos peticiones de los gobiernos para que entreguemos los datos de los usuarios, simplemente porque no los tenemos.
Y:
Nunca cumpliremos con ningún programa de vigilancia voluntario
Así que parece que, al menos – estás bastante a salvo de las miradas indiscretas del gobierno. El otro problema con StartPage son los absolutos resultados de búsqueda. Esto se debe a que Google lleva a cabo una campaña de censura masiva (https://www.naturalnews.com/2019-04-09-leaked-memos-prove-google-is-a-massive-criminal-enterprise-felony-election-meddling-and-racketeering.html), eliminando cualquier contenido alternativo o conspiranoico. Esto significa que incluso obtendrás resultados que no se relacionan con tu consulta en absoluto – y lo he confirmado con pruebas. Intenta buscar algo como “¿fue falso el tiroteo de Christchurch?” y verás lo que quiero decir. Luego compara con Qwant o DDG. Hice esto para muchas otras consultas que resultarían en mostrar sitios web alternativos o conspirativos (si el motor de búsqueda fuera honesto, es decir), pero en su lugar me mostró basura irrelevante. Además, al igual que Google, no admite otras formas de búsqueda aparte de Web e Imágenes. StartPage funciona perfectamente con JavaScript deshabilitado y tiene la práctica función “Vista anónima”, que permite visitar los sitios devueltos sin revelarse a ellos (sin embargo, gran parte de la funcionalidad estará deshabilitada).
Interesantemente, hace mucho tiempo StartPage solía tener un motor de búsqueda llamado IxQuick que usaba su propio índice. Lo utilicé mucho cuando existía y los resultados eran bastante buenos AFAIK. ¿Por qué lo quitaron y lo sometieron completamente a la red de bots de Google? Podríamos haber tenido un motor de búsqueda real basado en la privacidad con sin dependencia de los gigantes tecnológicos y sin censura (ya que StartPage no parece creer en ella, a diferencia de Qwant). Pero con la situación como está, yo no puedo recomendar StartPage en absoluto debido a los resultados censurados y a que comparte los datos de tu sistema con Google. Utilízalo sólo para emergencias cuando realmente necesites el enorme índice web de Google. ACTUALIZACIÓN: en realidad, al diablo con eso. StartPage acaba de ser literalmente comprado por una empresa de publicidad (https://www.techrights.org/2019/10/16/startpage-is-surveillance/) y también hizo un artículo de relaciones públicas al estilo Mozilla (https://www.startpage.com/blog/company-updates/startpage-and-privacy-one-group/) defendiendo la adquisición. Actualización noviembre 2020: ahora se volvieron totalmente autoritarios, odiando el TOR, las VPNs y hasta los “navegadores privados”:
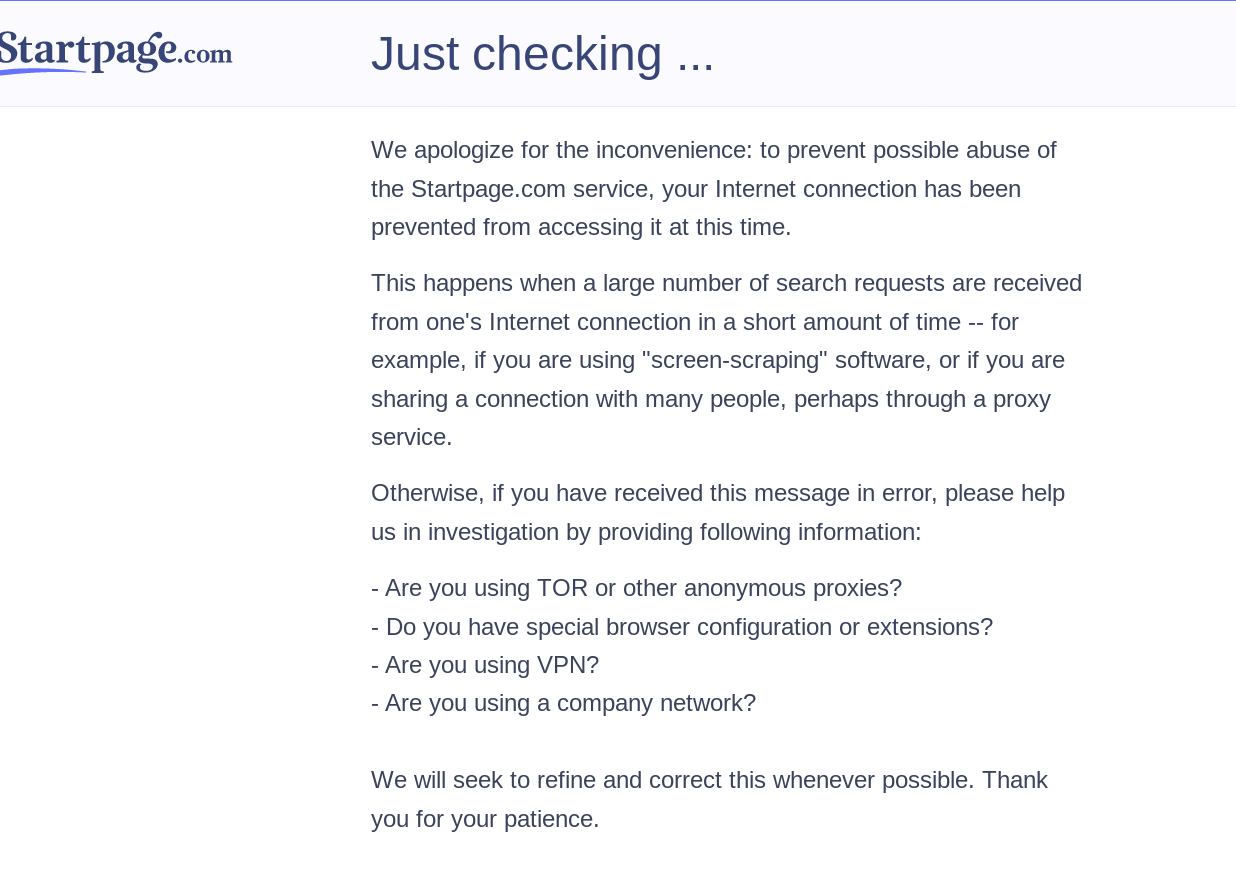
Esto me recuerda a las comprobaciones maliciosas del navegador de Cloudflare, donde comparan tu configuración con lo que ellos consideran “seguro” para decidir si te dejan pasar. Esto lo descubrí en noviembre, pero seguramente ya existía desde antes. Para ser honesto, siempre sentí que algo estaba mal en estos tipos; su imagen era “demasiado limpia”, si sabes a qué me refiero. Ahora tenemos la prueba de que para ellos, “la privacidad” sólo ha servido como un eslogan útil; en realidad nunca les ha importado una mierda. Por lo tanto, puedo aconsejar honestamente evitar por completo estos fraudes ahora!
Wiby.me

Un nuevo e interesante motor de búsqueda dedicado a sitios webs personales y de la vieja escuela. Realmente recomiendo echarle un ojo – y puedes literalmente apoyar la creación de un Internet mejor enviando sitios web a él (si conoces uno bueno, realmente deberías hacerlo). ¡No se permiten grandes corporaciones aquí! No requiere JavaScript (de hecho, no hay ni un solo script en su página). Mantiene los registros durante 48 horas (https://wiby.me/about/pp.html).
DuckDuckGo

“El motor de búsqueda que no te rastrea!” O al menos, eso es lo que afirma. El marketing es hábil y debo admitir que me enamoré de él inicialmente y fui un fan durante mucho tiempo – pero para ser honesto, había siempre banderas rojas. DuckDuckGo alberga un sitio de privacidad (https://spreadprivacy.com/) con algunas guías estupendas. Han refutado (https://spreadprivacy.com/three-reasons-why-the-nothing-to-hide-argument-is-flawed/) mitos (https://spreadprivacy.com/do-not-track/) y ha perseguido a gigantes como Google (https://spreadprivacy.com/google-filter-bubble-study/) – siempre un punto a favor en mi mente y una gran razón para considerar a un proveedor digno de confianza. Su cuenta de Twitter publica cosas de privacidad todo el tiempo, etc. A primera vista, DDG parece un grupo de personas como tú y yo, que buscan proteger su privacidad y crear un servicio para hacerlo (a diferencia de la manipulación de Mozilla). Desafortunadamente, como los grandes magos que son, han hecho una ilusión realmente convincente – pero sigue siendo una ilusión; y voy a mostrar cómo.
Como ya he dicho, las banderas rojas siempre estuvieron ahí. Gabriel Weinberg -el fundador de DuckDuckGo- solía dirigir la Base de datos de nombres (https://web.archive.org/web/20070116141500/http://namesdatabase.com/explanation.htm?c=0), una red social que te permitía reconectar con tus viejos amigos del colegio. Sin embargo, la función más importante -el envío de mensajes- estaba bloqueada tras un muro de pago que podía saltarse si invitabas a 24 personas a la red. Afirmaban que podías eliminarte de la base de datos si querías:
Permitimos que las personas se eliminen a sí mismas de la base de datos de nombres en cualquier momento, lo que elimina de forma instantánea y automática cualquier información personal asociada al perfil eliminado de la base de datos de nombres.
Sin embargo, el servicio no respetaba realmente al usuario (https://web.archive.org/web/20030628042441/http://namesdatabase.com/terms.html):
(e) Los Términos pueden ser modificados únicamente por la Compañía publicando los cambios en los Términos en el Sitio Web. Cada vez que el Usuario acceda al Sitio Web, se considerará que ha aceptado dichos cambios en vigor en el momento del acceso.
Sólo por visitar el sitio web has aceptado todos sus términos (¿y si han incluido una línea “podemos matarte mientras duermes”) mientras no mirabas? Jaja.
(a) La empresa es propietaria de toda la información que se le envíe, independientemente de quién o qué la envíe, qué se envíe o cómo o por qué se envíe. Dicha información incluye, pero no se limita a, toda la información enviada por el Usuario o sobre el Usuario y cualquier Información del Usuario enviada durante la membresía o a través del uso normal del Sitio Web y los servicios disponibles a través de él.
(b) Cualquier sucesor o cesionario de la Compañía adquirirá por defecto para su propio uso, de acuerdo con los Términos, toda la información recopilada por la Compañía, incluyendo pero no limitándose a toda la información asociada con el Sitio Web como se especifica en la sección 2(a) anterior.
Así que todo lo que enviaste allí dejó de ser tuyo (o incluso si otra persona publicó tus datos personales), y podría haber sido transferido a cualquier otra empresa (https://web.archive.org/web/20060329063012/http://namesdatabase.com/terms.html?c=). Las versiones posteriores del acuerdo contenían cosas aún más atroces como:
Opobox se reserva el derecho (pero no la obligación) de eliminar o editar su información
No puede … “metabuscar” en ningún Sitio Web de Opobox; (f) falsificar encabezados o manipular de otro modo los identificadores cuando se comunique de alguna manera con los Sitios Web de Opobox … utilizar la minería de datos o cualquier herramienta de recopilación o extracción de datos; (k) copiar, reproducir, modificar, crear trabajos derivados, distribuir o mostrar públicamente cualquier contenido (excepto Su Información) de los Sitios Web de Opobox;
Así que no puedo cambiar mi agente de usuario; usar wget, httrack o curl; o incluso hacer una captura de pantalla del sitio. Una mierda muy curiosa. Y todo esto son cosas que el posterior fundador de DDG aceptó. Luego vendió la base de datos a otra empresa, Classmates.com (https://www.sec.gov/Archives/edgar/data/1142701/000110465906033409/a06-9620_110q.htm), que añadió esto al acuerdo:
Al registrarse en los sitios web de Opobox, como beneficio adicional también se registrará automáticamente en Classmates.com, que es propiedad y está operado por Classmates Online, Inc. (“Classmates”), la empresa matriz de Opobox. Para completar este registro en Classmates.com, usted da su consentimiento para que Opobox proporcione Su información a Classmates. Los servicios de Classmates se proporcionan de acuerdo con sus propios Términos de Servicio y Política de Privacidad.
Así que el gurú de la privacidad que luego fundó DuckDuckGo vendió todos tus datos a una empresa aún menos ética (https://en.wikipedia.org/wiki/Classmates.com). Habrá tenido un repentino cambio de opinión y habrá creado la ubérrima DDG que respeta la privacidad? Vamos a comprobarlo:
DuckDuckGo solía afirmar en su política de privacidad que no se utilizaban cookies por defecto, pero hace unos años resultó que estaban estableciendo una cookie de un tercero (https://archive.is/qntuk), en contra de su política. Sólo estaba en su página de ayuda y lo arreglaron bastante rápido. Entonces, ¿eso es todo lo que tengo? ¿Una cookie de hace años?
En su Política de privacidad (https://duckduckgo.com/privacy) proclaman con orgullo, en letras grandes, que “no recogen ni comparten información personal”. La gran pregunta aquí, por supuesto, es qué se entiende por “información personal”. Resulta que, al menos para DuckDuckGo, las consultas de búsqueda por sí solas no son personales -incluso si buscas algo que sólo tú podrías saber. Estoy bastante seguro de que la mayoría de la gente no estaría de acuerdo con eso. DuckDuckGo afirma que está bien si no almacena el agente de usuario o la dirección IP junto con la búsqueda, aunque:
También guardamos las búsquedas, pero de nuevo, no de una manera personalmente identificable, ya que no almacenamos direcciones IP o cadenas de agentes de usuario únicas. Utilizamos datos de búsqueda agregados y no personales para mejorar cosas como los errores ortográficos.
Cuál es el contenido de estos datos de búsqueda no personales, por supuesto, no se indica. Son realmente sólo las consultas de búsqueda que guarda DDG? Sí sabemos que, por ejemplo, DuckDuckGo rastrea el uso de Pale Moon a través de un parámetro en la consulta de búsqueda (“?t=palemoon”), que está ahí por defecto. Es probable que esto también ocurra para sus otros socios (https://help.duckduckgo.com/company/partnerships/). No es eso ya personal? No se podría utilizar para enlazar sus búsquedas? Lo curioso es que DuckDuckGo se ha pasado gran parte de su política de privacidad criticando a Amazon por filtrar sus consultas de búsqueda (https://techcrunch.com/2006/08/06/aol-proudly-releases-massive-amounts-of-user-search-data/), que pudieron ser vinculadas a usuarios individuales porque jodieron su anonimización. Pueden asegurar que esto tampoco se pudo hacer con las búsquedas guardadas de DuckDuckGo? Al fin y al cabo sí que rastrean otra información como he mostrado antes. Como dice la propia DDG (https://spreadprivacy.com/data-anonymization/), “Los únicos datos verdaderamente anonimizados son los que no existen” – así que ¿por qué no almacenar las consultas de búsqueda? Del artículo de techcrunch:
El problema más grave es el hecho de que muchas personas suelen buscar su propio nombre, o el de sus amigos y familiares, para ver qué información está disponible sobre ellos en la red. Si se combinan estas búsquedas sobre el ego con las consultas sobre porno, se produce una grave vergüenza. Combínelas con “comprar éxtasis” y tendrá pruebas de un delito. Combínalo con una dirección, un número de la seguridad social, etc., y tienes un robo de identidad a punto de producirse. Las posibilidades son infinitas.
¿Cuánto tiempo almacena DDG las consultas de búsqueda? ¡Eso no se explica! Lo que sí admiten es que “cumplirán con las peticiones legales ordenadas por los tribunales”. ¿Qué podrían hacer las fuerzas del orden si encontraran consultas que sólo yo podría haber buscado? ¿Podrían utilizarlas en mi contra? Ni idea, pero prefiero que eso no ocurra. Entonces, DuckDuckGo admite que ejecuta experimentos con sus usuarios (https://help.duckduckgo.com/privacy/atb/):
En primer lugar, puedes notar que cuando buscas en DuckDuckGo, puede haber un parámetro URL “&atb=” en la dirección web en la parte superior de tu navegador. Este parámetro nos permite realizar pruebas A/B (split) anónimas de los cambios de producto que hacemos en DuckDuckGo.
En segundo lugar, medimos el compromiso de eventos específicos en la página (por ejemplo, cuando se muestra un mensaje de error ortográfico y cuando se hace clic en él). Esto nos permite realizar experimentos en los que podemos probar diferentes mensajes de faltas de ortografía y utilizar el CTR (índice de clics) para determinar la eficacia del mensaje.
Por ejemplo, nuestras extensiones de navegador y aplicaciones móviles enviarán una petición atb.js con cada búsqueda realizada. Estas peticiones nos permiten contar aproximadamente cuántos dispositivos han accedido a DuckDuckGo
¡Eso es bastante información, y justo después de criticar la llamada recogida anónima de datos! Esto es exactamente lo que he criticado a Mozilla por hacer y de hecho lo que me llevó a reescribir toda esta sección (y el artículo). Gabriel Weinberg se ha mostrado hipócrita y ha roto la confianza en muchas ocasiones. Por una reciente, ha puesto su servicio de venta de camisetas detrás de Cloudflare (un MITM) (https://duckduckgo.merchmadeeasy.com/) sin notificar al comprador de ninguna manera. Entonces, ¿cuál es el veredicto final sobre DDG?
Mirando sólo la superficie, todavía se podría poner en el nivel alto – no hay almacenamiento de IP ni la mayoría de los otros datos que los proveedores de búsqueda suelen recoger. No se hacen peticiones de terceros. Hay una versión sin JS (resultados no van más allá de la primera página) y alojan un servicio oculto de Tor (https://3g2upl4pq6kufc4m.onion/) (que bloquea los navegadores que no son TBB – probado con Iridium). En cuanto a las cosas no relevantes para la privacidad: los resultados de las búsquedas son jodidamente buenos; se utilizan Bing y Yahoo para ellos, así como su propio rastreador. Más que eso: DDG muestra “respuestas instantáneas” de más de 400 fuentes diferentes en la esquina superior derecha de la ventana. Tiene anuncios que se pueden desactivar en la configuración. Además de los sitios habituales, DDG puede buscar imágenes, vídeos (sólo resultados de YouTube) y noticias. Sin embargo, si se profundiza en el tema, se observan varios problemas graves con la falta de fiabilidad y confiabilidad del fundador. Está claro que no se preocupa de verdad por ti ni por tu privacidad, como demuestra la reciente inclusión de Cloudflare. Siendo el gran hombre de negocios que es, ha fingido muy eficazmente que lo hace y se ha aprovechado mucho de los recientes sustos de privacidad. Así que, si sólo te importa la privacidad / funcionalidad pura, DDG es bastante bueno todavía – pero debido a la base ética inestable y suficientes grietas si se mira lo suficiente, yo no puedo recomendarlo con tanto entusiasmo como lo hice antes. Se podría decir que es el Tutanota de los motores de búsqueda – lo suficientemente bueno como punto de entrada, pero se puede hacer mejor. Sin embargo, no hay nada que se acerque al nivel del servicio de correo electrónico de RiseUp, por lo que DuckDuckGo sigue siendo una opción viable para el uso regular.
Qwant

Olvídate de la privacidad – este buscador tiene dos fallos importantes; en primer lugar, te lanza un captcha todo el puto tiempo si usas anonimizadores. En segundo lugar, se comerá aleatoriamente las consultas de búsqueda que escribas a través del plugin o cuando te lance el captcha, por lo que tendrás que volver a escribir. Apenas es utilizable, pero sigue leyendo si quieres saber más sobre él.
Un motor francés que dice ser totalmente privado (https://about.qwant.com/legal/privacy/):
Nunca intentamos averiguar quién es usted o qué hace personalmente cuando utiliza nuestro motor de búsqueda.
Por principio, Qwant no recoge datos de sus usuarios cuando buscan. Simple y llanamente.
La política anterior sería simplemente perfecta si se cumpliera. Pero no parece serlo:
No recogemos ni almacenamos ningún historial ni tus búsquedas. Cuando realizas una búsqueda, tu consulta se anonimiza instantáneamente disociándose de tu dirección IP, de acuerdo con lo que aconseja el controlador de datos francés.
Si analizamos detenidamente esta vaga (¿a propósito?) redacción, podemos ver que deja la posibilidad de almacenamiento de IP y de consultas de búsqueda. Al fin y al cabo -si no las almacenaran-, ¿qué es exactamente lo que se está “desvinculando de mi dirección IP”? Y si no almacenan la IP, las consultas no tendrían nada que disociar. Claro que la otra interpretación es que en realidad no almacenan nada de eso. Suponiendo que se trate de franceses, hay una posible barrera lingüística en este caso. Sin embargo, debería haber sido fácil decir simplemente “no almacenamos su dirección IP ni sus consultas de búsqueda en absoluto”. Pero no lo hicieron – ¿por qué el “controlador de datos francés” no les avisó de esto si de hecho no lo hacen? De nuevo, puede que esté sobreanalizando esto, pero la política de privacidad no asegura al 100% que estos datos no se almacenen.
Otra ventaja de Qwant es el uso de su propio índice de sitios:
Continuamos nuestros esfuerzos para indexar toda la diversidad de la web. Nuestros rastreadores visitan incesantemente la Web global para perfeccionar nuestros resultados.
Admiten que aún no han indexado completamente Internet, por lo que se obtendrán resultados de Bing para complementar los propios de Qwant. Pero debemos esperar que Qwant acabe finalmente el trabajo (https://betterweb.qwant.com/en/web-indexation-where-does-qwants-independence-stand/) / (“El cambio hacia la independencia total es, por tanto, progresivo, y esa es, efectivamente, la dirección que ha tomado Qwant, ¡difícil de ver desde fuera!”), y entonces, tendremos un motor de búsqueda real que no envía sus peticiones a ningún otro sitio, impidiendo que Microsoft, Google u otros infractores pongan sus manos en nuestras consultas de búsqueda, pudiendo bloquear a Qwant o censurar las búsquedas. Hablando de censura, Qwant pretende ser imparcial (https://about.qwant.com/):
Qwant permite que toda la Web sea visible sin ninguna discriminación y sin ningún sesgo. Nuestros algoritmos de ordenación se aplican por igual en todas partes y para todos los usuarios, sin tratar de adelantar sitios web u ocultar otros en función de intereses comerciales, políticos o morales
Y de su página de filosofía (https://help.qwant.com/help/overview/our-philosophy/):
Qwant presenta la realidad de un mundo complejo, con opiniones diversas, que lo hacen rico y digno de ser vivido.
Sin embargo, en contra de lo anterior, han inexplicablemente firmado un acuerdo de censura (https://www.rnz.co.nz/news/national/389297/tech-companies-and-17-govts-sign-up-to-christchurch-call). No sólo eso, sino que permiten la denuncia de contenidos (https://about.qwant.com/legal/terms-of-service/qwant-search/):
En el caso de que al navegar por los Servicios observes contenidos que puedan estar relacionados con la apología de los crímenes contra la humanidad, la provocación o apología de actos de terrorismo, la incitación al odio racial, hacia las personas por razón de su sexo, su orientación o identidad sexual o su discapacidad, la pornografía infantil, la incitación a la violencia, los atentados contra la dignidad humana, tienes la opción de hacérnoslo saber
Y -aunque no he podido detectar ninguna censura a través de mis pruebas- sí confirman que la eliminación de ciertos resultados es posible:
Al solicitar que un contenido sea retirado de la lista de QWANT, si obtiene una respuesta positiva por nuestra parte
Entonces, debemos considerar que se trata de un motor amigo de la censura. Cuáles son otras peculiaridades de Qwant? Puede buscar imágenes, noticias, vídeos (sólo en YouTube), compras (¿no hay resultados?), sitios sociales (sólo en Twitter) y música, además de la web normal. La versión con JavaScript es lenta y rompe Pale Moon a veces, pero hay una Sin JavaScript (https://lite.qwant.com/) disponible también (aunque esa carecerá de las prácticas respuestas instantáneas). Actualización de agosto de 2020: ahora muestra cero resultados, por lo que la única opción es la de JS. ¡Tiene una funcionalidad de Mapas que respeta la privacidad! Desgraciadamente no hay Vista Anónima a’la StartPage o un dominio Tor.
¿Cuál es el veredicto, entonces? Genial si la política de privacidad es poco clara (tratando de asumir las mejores intenciones aquí…), en su mayoría el uso de índice propio y no requerir JavaScript son puntos a favor. La falta de resultados de búsqueda (en las otras categorías, al menos), la ausencia de proxy o Tor y la posible censura son desventajas. Yo lo evitaría en principio sólo por esto último, pero las ventajas (que no se encuentran juntas en ningún otro sitio excepto en Mojeek, cuyo índice y privacidad son mucho más débiles) podrían superarlo para algunos. Lo más importante es que el bloqueo del anonimizador y las consultas de búsqueda que no pasan hacen que Qwant no merezca la pena.
MetaGer
Este de Alemania también se anuncia como privado, pero no sólo almacena tu IP…
Sólo para este fin, se almacena la dirección IP completa y una marca de tiempo durante un máximo de 96 horas
…sino que también comparten una parte de ella con los anunciantes:
Para recibir esta publicidad, damos los dos primeros bloques de la IP en relación con partes del llamado agente de usuario a nuestros socios publicitarios.
Entonces, su sitio web recoge y almacena los siguientes datos durante un máximo de una semana:
Su dirección IP, el nombre y la URL del archivo recuperado, la fecha y la hora de acceso, el referente que envió, el agente de usuario que envió
Así que, como podemos ver, MetaGer no es tan bueno para la privacidad. Una sección posterior dice lo siguiente:
Cuando se utiliza el plugin MetaGer, se generan los siguientes datos:
Dirección IP: No será almacenada ni compartida.
User-Agent: No se almacenará ni se compartirá.
Sería fácil asumir que la búsqueda a través del plugin de MetaGer (a diferencia de su sitio) no almacena registros, pero eso sería ingenuo y erróneo. De hecho, la primera frase de la sección “Acumulación de datos por contexto” desmiente esta interpretación:
Cuando se utiliza nuestro buscador web MetaGer a través de su formulario web o a través de su interfaz OpenSearch, se generan los siguientes datos:
Y luego viene lo del almacenamiento de la IP y todo eso. Así, todo lo anterior significa que el uso del plugin no almacena ningún dato adicional sobre lo que ya hace el propio sitio. Por lo tanto, la privacidad de MetaGer no es tan buena, pero al menos obtienes un servicio de mapas que no almacena registros:
Al utilizar el servicio de mapas de MetaGer, se generan los siguientes datos:
Dirección IP: No será almacenada ni compartida.
User-Agent: No se almacenará ni se compartirá.
Consulta de búsqueda: No se almacenará ni compartirá.
Datos de ubicación: No se almacenarán ni compartirán.
Los resultados de búsqueda provienen de Bing y Scopia, este último da unos resultados absolutamente terribles (creo que puede ser el propio crawler de MetaGer – se puede desactivar y depender sólo de Bing). Sólo tiene categorías para sitios regulares, imágenes y compras (que trae resultados de algún sitio inútil “Keikoo”). Funciona muy bien con JavaScript desactivado, pero no se puede guardar la configuración sin cookies (aunque no tiene mucho sentido configurarlo en absoluto – realmente, sólo la Búsqueda Segura si te importa eso). No hay respuestas instantáneas como con DDG o Jive. Incluye un proxy a través del cual puedes ver los sitios web devueltos de forma anónima, y tiene un dominio de cebolla (http://b7cxf4dkdsko6ah2.onion/tor/) (que requiere resolver un captcha en cualquier cosa que no sea el Navegador Tor). Estas dos características son las únicas razones para usar MetaGer; de lo contrario, sufre de privacidad débil y resultados de búsqueda débiles – dos de las principales cosas que nos importan cuando calificamos un motor de búsqueda. Al menos, su política es clara, concisa y no contiene posturas innecesarias, lo cual es encomiable, supongo.
Jive Search (Muerto)
Otro con aparentemente cero registros – “no almacenamos tus términos de búsqueda, dirección ip ni información sobre tu navegador.” – e incluso tiene un dominio Tor. Soporta la búsqueda sólo de sitios regulares (resultados provenientes de Yandex – de muy alta calidad según mis breves pruebas) e imágenes (por otro lado, éstas apestan). Proporciona respuestas instantáneas similares a las de DDG y SearX, así como enlaces proxy (con JS despojado para evitar el seguimiento y la desanonimización). Al igual que con Ecosia, MetaGer y StartPage – depender de una sola fuente para los resultados, independientemente de su calidad, está sujeto a eventuales sesgos y censura. Eso, así como una personalización absolutamente nula (no se puede cambiar el tema básico y feo por defecto, o incluso desactivar el autocompletado) significa que es probablemente peor que DDG. Edito: lo he bajado ya que la cantidad de resultados se está cortando por alguna razón. Aparentemente el motor en sí contiene mucha más funcionalidad (https://github.com/jivesearch/jivesearch) – pero la instancia actual apesta (https://jivesearch.com), y eso es lo que estoy calificando.
Mojeek

El único que utiliza completamente su propio crawler – y se refleja visiblemente en los débiles resultados de búsqueda. Por ejemplo, a menudo no se encontrarán respuestas técnicas o científicas específicas. Sin embargo, se evita el deranking de contenidos alternativos de Google (y en menor medida de Bing) (https://www.mariehaynes.com/resources/scientific-consensus/) y la promoción injustificada de los grandes medios de comunicación convencionales. La privacidad de Mojeek no es tan buena: los registros contienen “la hora de la visita, la página solicitada, posiblemente datos de referencia e información del navegador”; no se especifica la duración. Al menos no se comparte con terceros y las direcciones IP no se almacenan – aunque esto solía tener una advertencia:
si se considera que una consulta de búsqueda está relacionada con prácticas ilegales y poco éticas relacionadas con menores, entonces se guardará el registro completo, incluida la dirección IP del visitante, y se entregará con gusto a cualquier autoridad oficial que lo solicite
La cita ha sido eliminada recientemente de la política de privacidad (https://www.mojeek.com/about/privacy/), así que supongo que ya no hay vigilancia selectiva. También dicen que sólo lo han puesto para asustar a los entusiastas del PC y que la política de chivatazos nunca ha existido realmente, pero quién sabe hasta qué punto podemos confiar en eso. Aun así, tal vez deberíamos darles el beneficio de la duda hasta que ocurra un fiasco como el de RiseUp (https://archive.fo/bKFtd).
A pesar de los débiles resultados de búsqueda – este motor merece consideración por ser el único con índice propio que se preocupa remotamente por tu privacidad. Otro punto a su favor es que JavaScript no es necesario en absoluto incluso para las imágenes. Yo solía descartar a Mojeek porque asumía que te reportarían por cualquier consulta de búsqueda que no les gustara, pero tal vez exageré sobre una política de sólo ** que ahora ha sido eliminada de todos modos. Mojeek todavía prohíbe las consultas de ** y los sitios de ** no pueden ser encontrados en su índice (que es lo que todos los otros motores hacen, de todos modos – además de mucha más intromisión / censura). Con todo, por fin tenemos un motor de búsqueda independiente que es relativamente privado y no censura el contenido alternativo.
Ecosia

Su reclamo a la fama ha sido plantar árboles por cada 45 búsquedas (eso es una media) que hagas usando su servicio – pero esto, por supuesto, depende de que se muestren anuncios de Bing (y dudo que pueda contrarrestar la deforestación desenfrenada (https://digdeeper.neocities.org/ghost/capitalismcancer.html#deforestation), de todos modos). No es muy privado por defecto – “Por ejemplo, cuando haces una búsqueda en Ecosia reenviamos la siguiente información a nuestro socio, Bing: la dirección IP, la cadena de agente de usuario, el término de búsqueda, y algunas configuraciones como tu país y la configuración del idioma.” Sin embargo, dice respetar el encabezado DNT: “Si tienes activada la opción “Do Not Track” en la configuración de tu navegador, no recogemos ningún dato analítico. La mayoría de los otros sitios web ignoran esta configuración; creemos que los usuarios deberían tener una opción.” ¿La dirección IP forma parte de los datos analíticos? Dependiendo de cómo se interprete literalmente la información DNT, Ecosia puede convertirse en una opción bastante buena, que combina la ética y la privacidad. Puedes buscar sitios habituales, imágenes, vídeos, noticias y mapas. Sin embargo, los resultados de la búsqueda provienen exclusivamente de Bing. Funcionará sin JavaScript pero las imágenes no se mostrarán en absoluto.
Oscobo

Una supuesta privada con una política de privacidad no tan buena (actualizada por última vez hace 2 años…). Proclama con orgullo varias veces cómo no almacena información de forma que pueda identificarte (se puede ser más vago), sin embargo el mito de que esto es una práctica que respeta la privacidad ha sido desmontado (https://spreadprivacy.com/data-anonymization/). Y en realidad no dicen lo que almacenan y por cuánto tiempo – una admisión indirecta de que almacenan bastantes datos en realidad. Luego viene esta joya: “Oscobo utiliza cookies para determinar la eficacia de nuestras propias campañas de marketing”. Y lo más gracioso es que no veo que se establezca ninguna cookie en mi uMatrix (política de privacidad anticuada, como ya se ha mencionado; sin embargo, muestra que lo hicieron en un momento dado, o al menos lo planearon). Luego dice: “Oscobo utiliza tecnología propia para ocultar tu historial de búsqueda de otras personas que puedan utilizar tu dispositivo después de tu búsqueda. Esto puede salvarte de algunas situaciones embarazosas” Pero yo veo las consultas de búsqueda en mi historial de navegación, claro como el agua – así que esta afirmación fue un error también (y uno negativo esta vez). Oscobo puede buscar imágenes (sólo flickr – casi inútil), vídeos y mapas (incrustando google directamente, bostezo); no requiere JavaScript pero las imágenes no aparecerán entonces. De todos modos, debido a los problemas mencionados anteriormente, este motor de búsqueda no parece fiable en absoluto, y no lo recomiendo. No tiene nada sobre los más conocidos y para algo más gracioso, contiene un enlace directo a algún archivo ejecutable de “Oscobo Browser” sospechoso. Jaja – evitar.
DiscreteSearch

Para que funcione correctamente, este necesita todas las cookies, JavaScript y XHR habilitados. Qué se consigue con eso? Vamos a ver su política de privacidad (https://www.discretesearch.com/legal/siteprivacy):
Discrete Search no rastrea el historial de búsqueda de ninguna manera identificable por el usuario.
La gran mentira de los llamados buscadores privados vuelve a asomar su fea cabeza. La respuesta es la misma que a Oscobo – “identificable por el usuario” es vaga y suele incluir mucha información que puede revelarte si se junta (https://spreadprivacy.com/data-anonymization/). Por qué no mencionar simplemente qué cojones almacena y dejarnos decidir si estamos cómodos con ello? Graciosamente, la Búsqueda Discreta SÍ proporciona esa información después (a diferencia de Oscobo):
Además, almacenamos datos de búsqueda agregados para mejorar el rendimiento del producto, pero nunca almacenamos direcciones IP o identificadores de usuario únicos en relación con dichas búsquedas para garantizar que ninguna de la información recopilada en relación con su actividad de búsqueda sea personalmente identificable.
Así que los “datos de búsqueda agregados” se registran; aunque la parte importante viene a continuación. Si lees entre líneas, admiten que almacenan tu dirección IP así como “identificadores únicos de usuario”, sólo que supuestamente sin relación con las consultas de búsqueda. Y eso es lo que llaman privado? No, gracias. ¿Por qué confiar en la dudosa “desconexión” de alguien cuando podría simplemente no almacenar los datos? Y parece que Discreet Search almacena muchos de ellos, lo que aumenta el riesgo. Luego está esta joya de los TOS (https://www.discretesearch.com/legal/siteterms):
Usted certifica que posee todos los derechos de propiedad intelectual de su contenido. Por la presente, nos concede a nosotros, a nuestras filiales y a nuestros socios una licencia mundial, irrevocable, libre de regalías, no exclusiva y sublicenciable para utilizar, reproducir, crear obras derivadas, distribuir, ejecutar públicamente, mostrar públicamente, transferir, transmitir, distribuir y publicar su contenido y las versiones posteriores de su contenido con el fin de (i) perseguir nuestros intereses comerciales, (ii) distribuir su contenido, ya sea electrónicamente o a través de otros medios, a terceros que deseen descargarlo o adquirirlo de otro modo, y/o (iii) almacenar su contenido en una base de datos remota accesible para terceros. Esta licencia se aplicará a la distribución y el almacenamiento de Su Contenido en cualquier forma, medio o tecnología conocida actualmente o desarrollada posteriormente.
TL;DR todo lo que envíes o transmitas al motor pasa a ser de ellos (no sólo las consultas sino cosas como las cabeceras que envía tu navegador), y lo van a almacenar en bases de datos de terceros no especificadas. Ja, ja. Discrete Search pone los malditos anuncios de imágenes encima de tus búsquedas, una práctica que no he visto en ningún otro sitio. Al menos han cumplido la promesa de encriptar tus búsquedas localmente, a diferencia de Oscobo (sí, lo he comprobado). Aun así, evita este naufragio.
Gibiru
Afirma estar “Protegiendo tu privacidad desde 2009” en su página principal. Si lees su política de privacidad, todo cuadra: Gibiru no almacena registros ni cookies. Por supuesto, lo que han olvidado mencionar es que utilizan literalmente a Google directamente para sus resultados (sin proxiarlos, como hace StartPage o hacía Scroogle). Gibiru no funcionará sin habilitar los scripts de Google, por lo que todos los datos que supuestamente no recoge, Google los tomará alegremente en su lugar. Desafortunadamente – como puedes ver – los motores de búsqueda también tienen su parte justa de fraudes. ¡Evite!
Peekier

Cuando conocí Peekier después de calificar algunos buscadores poco estelares, me encantó encontrar por fin otro que respeta al usuario. No hay almacenamiento de IP, ni peticiones de terceros, ni registro de los datos que envía tu navegador (aparte de las consultas de búsqueda temporales – la misma política que DuckDuckGo). Además, tiene la práctica función de mostrar el sitio web resultante sin visitarlo – mostrándote la información relevante de forma eficiente. Y entonces veo esto:
Cloudflare, nuestro proveedor de caché, puede utilizar una única cookie de sesión para las medidas anti-DDOS.
Muy bien, así que mientras TÚ puedes no almacenar nada, Cloudflare -escondido en las sombras entre tú y yo- se lo llevará todo alegremente. Y esta afirmación, entonces, se convierte en una mentira:
SSL/TLS se aplica en todo el sitio web. No se transmite ninguna información sin cifrar a través de Internet.
Debido a que Cloudflare desencripta la petición en sus servidores, no se puede decir que la información esté encriptada durante todo su recorrido. Dado que Cloudflare podría ser el mayor mal actual de Internet (https://web.archive.org/web/20190813174848/https://codeberg.org/themusicgod1/cloudflare-tor/src/branch/master/readme/en.md), no puedo dejar pasar este aparentemente pequeño punto. Por supuesto, Peekier también afirma que “no utiliza cookies de ninguna manera para rastrearte o almacenar datos de identificación personal”, pero requiere una cookie de Cloudflare para funcionar (que es literalmente una cookie de rastreo), así como habilitar JavaScript. Y eso, amigos míos, arruina un buscador que podría haber encabezado la lista.
FindX
No debía reseñar más buscadores, pero este está haciendo una imitación tan genial de Mozilla (fingiendo ser privado siendo la realidad otra) que no podía dejar pasar este escrito. Para ser honesto, nunca he oído hablar de FindX y probablemente no lo haría si un lector no me lo mencionara – pero el nivel de su falsificación de privacidad es tan grande que merece un lugar orgulloso como la última entrada en este informe. Echemos un vistazo a su página de información (https://www.findx.com/about) primero:
Findx es un motor de búsqueda para usuarios que valoran la privacidad. No recopilamos información sobre usted cuando realiza búsquedas, a diferencia de la mayoría de los motores de búsqueda. Por favor, lee los detalles en nuestra Política de Privacidad. Si te preocupa que las empresas creen perfiles invisibles de ti basándose en tus búsquedas y hábitos de navegación por Internet, Findx es para ti.
Lo demás que hay no es muy relevante. Recuerda las citas anteriores mientras inspeccionamos su Política de privacidad (https://www.findx.com/privacy). Empieza con lo habitual del GDPR, pero curiosamente parece que intenta escurrir el bulto, o no explicar bien, muchos de esos derechos que supuestamente tienes. Por ejemplo:
Puedes solicitar que restrinjamos el uso de tus datos personales. Sólo estamos obligados a cumplirlo en determinadas circunstancias.
Y de la sección 9:
Podemos pedirle información adicional para confirmar su identidad y por motivos de seguridad, antes de revelar los datos personales solicitados. Nos reservamos el derecho a cobrar una tarifa cuando lo permita la ley, por ejemplo, si su solicitud es manifiestamente infundada o excesiva.
Ahora compara lo anterior con cómo Qwant trata la GDPR (https://about.qwant.com/legal/privacy/). Pero como no le doy mucho valor a estas leyes en absoluto, pasemos a los apartados más importantes, es decir, “3.2 Findx Search”, que nos dirá lo que realmente recoge su motor.
[…] los datos se transfieren a nuestros socios de búsqueda que sólo los utilizan para ofrecer mejores resultados de búsqueda en Findx
Así que un “socio” no era suficiente, tenían que ser dos: CodeFuel y Microsoft. FindX también afirma descaradamente que “Microsoft valora tu privacidad” – ¿te lo puedes creer? De todos modos, ¿cuáles son los datos que se envían?
Dirección IP, cadena de agente de usuario, término de búsqueda, configuración del país y del idioma, configuración del filtro de contenido para adultos, configuración del filtro de búsqueda activa (por ejemplo, información del número de página), un ID de Bing opcional (lea más abajo) y el ID de la organización que debería beneficiarse de su búsqueda.
Así que el respetuoso FindX comparte prácticamente todo lo posible con no uno, sino dos terceros! Tienen una explicación para eso? Seguro que sí – pero te advierto – esto será una de las cosas más idiotas que hayas leído en Internet. Será mejor que te pongas un casco, porque el rayo de la estupidez está llegando
“Pero sigues pasando mi dirección IP a CodeFuel y Bing”. Sí, tenemos que hacerlo. Protegemos tu privacidad al máximo permitido por el acuerdo que tenemos con ellos. Otros motores de búsqueda centrados en la privacidad enmascaran parte de su dirección IP antes de transmitirla a sus socios, pero nosotros no podemos hacerlo. Es una cuestión de confianza. Tienes que confiar en que los buscadores centrados en la privacidad no transmiten tu dirección IP completa a sus socios. En Findx, tienes que confiar en que nuestros socios sólo la utilizan para lo que dicen que van a hacer, que es proporcionar mejores resultados en nuestro sitio (solamente) – nada más. Confiamos en ellos.
Vaya, me ha caído un huracán de despropósitos y estoy tan confundido que no sé ni por dónde empezar con esto. Admiten literalmente que son peores que el resto de buscadores -ya que esos (como Swisscows o StartPage) sí que limitan los datos enviados a los proveedores que utilizan-. FindX simplemente dice a la mierda y vuelca toda tu información en Bing, luego te dice que sólo confíes en sus socios para cumplir con un acuerdo que nunca se especifica realmente aparte de las vagas afirmaciones de “mejores resultados de búsqueda”. Suena peligrosamente parecido a “mejorar tu experiencia” de Mozilla mientras abusan de todos tus datos. ¿Y por qué iba a someterse Microsoft a una empresa de poca monta como FindX? Es más probable que hagan lo que les dé la gana con tus cosas. ¿Qué hay del otro socio, CodeFuel?
Cuando se muestran los resultados de la búsqueda, los píxeles de seguimiento revelan a nuestro socio de búsqueda cuáles de los resultados y anuncios que recibimos fueron realmente vistos por usted. Nuestro socio, CodeFuel, sólo utiliza esta información para construir métricas para nosotros y estadísticas sobre el uso del servicio. La información no se vende ni se comparte con empresas de publicidad. Simplemente nos proporciona información sobre los ingresos y diversas estadísticas como cuántas búsquedas dieron lugar a la visualización de anuncios, cuántos usuarios únicos realizaron búsquedas, en cuántos resultados se hizo clic, etc.
Entonces, FindX nos asegura que la recolección de datos de CodeFuel es bastante suave. Pero su política de privacidad (archivo) cuenta una historia diferente:
Cierta información relacionada con el uso en relación con su uso e interacción con su dispositivo, incluido el Software y los Servicios y Otro Software, como cuándo y cómo utiliza el Software y los Servicios y Otro Software, cómo utiliza su navegador de Internet y las aplicaciones relacionadas con la búsqueda en Internet, su configuración de idioma, las páginas web que visita, las aplicaciones que utiliza y el contenido que ve, al que accede y que utiliza en dichas páginas web y aplicaciones; por ejemplo, las ofertas y los anuncios que ve, utiliza y a los que accede, cómo los utiliza y su respuesta a ellos (es decir. datos de clickstream), la frecuencia con la que los utiliza, sus consultas de búsqueda y la ubicación, hora y fecha no precisas de sus búsquedas
Aunque FindX afirma explícitamente en su FAQ (https://www.findx.com/faq) que estos datos no se comparten con terceros…
CodeFuel actúa como “intermediario” entre los pequeños y medianos socios y Microsoft, y les pasa los datos para servir resultados de búsqueda y anuncios. CodeFuel utiliza esta información para elaborar métricas y estadísticas sobre el uso del servicio. La información no se vende ni se comparte con nadie
CodeFuel sí afirma directamente en varias ocasiones que lo hace:
Al realizar la detección y prevención del fraude, utilizamos los servicios de terceros que recibirán y accederán a su PII.
También utilizamos su IIP para cumplir con los requisitos legales y reglamentarios […] Para ello, podemos compartir su información con las fuerzas de seguridad u otras autoridades competentes y cualquier tercero […] También compartiremos esta información con nuestros asesores profesionales en el ámbito de este propósito.
También podemos compartir su información con nuestras empresas subsidiarias, afiliadas y matrices en virtud del interés legítimo para la prestación del Software & Servicios a usted, pero su uso de dicha información debe cumplir con esta Política de Privacidad.
Así que dos “socios” se convirtieron en quién coño sabe cuántos. Hay mucha más suciedad en FindX – su sitio web también recoge un montón de datos, TOS más o menos te hace un esclavo, etc. Pero no quiero pasar más tiempo en este buscador de mierda que el absolutamente necesario. No hace falta decir que no es nada privado y que, de hecho, probablemente sea mejor usar Bing directamente, ya que FindX envía todo allí de todos modos, mientras que también ejecuta su propia operación de espionaje (por no mencionar que CodeFuel y sus socios también ponen sus sucias manos en tus datos). Este es probablemente el motor de búsqueda más deshonesto que existe, rivalizando con VFEmail y Hushmail en su desvergüenza.
Resumen
Así que la primera edición de este resumen fue excesivamente positiva. Estaba ansioso por compartir por fin algunas buenas noticias después de que la situación de Mozilla, Proton y otros ensuciaran el clima de privacidad. Sin embargo, sobreestimé la situación y sobrevaloré varios motores de búsqueda como StartPage, MetaGer y DuckDuckGo. El principal problema es que todos ellos carecen de índice propio, lo que significa que son dependientes de los infractores. Los que sí utilizan su propio índice tienen resultados débiles. Esto ya demuestra que la situación es peor que con los navegadores (que tiene el independiente Pale Moon así como varios otros proyectos más pequeños y menos viables) o el correo electrónico. No sólo no hay ningún proveedor que se acerque a la calidad de RiseUp mail, sino que incluso los proveedores de correo electrónico de segundo nivel (como Posteo o Dismail) superan a los mejores buscadores. Además, este campo está plagado de fraudes, al igual que el correo electrónico. ¿Qué puede hacer entonces un mal usuario? Lo mejor sería desenchufarse y lidiar con los inconvenientes de los terribles resultados, aunque, por supuesto, es difícil hacerlo realmente. Sin embargo, la situación no mejorará hasta que apoyemos a los motores de búsqueda independientes. Así que, utiliza Mojeek y Wiby para conseguirlo. Si no estás preparado para deshacerte de los infractores, una buena instancia de SearX es tu mejor opción. Es triste cómo, para la mayoría de ellos, los resultados no pasan de la primera página (ilustrando el fracaso del movimiento FOSS). Recomiendo destetarse de Google ya que están tan censurados, por lo tanto StartPage está fuera. El guerrero de la privacidad herido sigue marchando, raspando hasta que un proveedor decente finalmente aparezca…
Truly a masterpiece of content.
Every sentence here adds value.